Parallel patterns
According to Wikipedia, a software design pattern is “a software design pattern is a general, reusable solution to a commonly occurring problem within a given context in software design”.
As a simple example, in the context of structural design of an algorithm, a repeated access of a vector/array item for a given index can be expressed with a loop structure instead of repeatedly accessing the vector updating the index manually. All commonly used programming languages have support for loops.
The context I am concerned with in this series of blog posts is parallel computing. Parallel computing is a very broad topic, so for now, let’s restrict ourselves to the the kind of parallelism you get from muiltiple cores/cpus sharing memory. This is the kind of parallism you have in all processors you find today in your average computer. Where applicable, I will make references to additional kinds of parallelism available, in particular vector parallelism (aka SIMD) and GPU-style parallelism (aka SIMT) where applicable.
Illustrating patterns
Let’s begin with some simple code and its graphical representation which will be used to show-case parallel patterns later on.
1 F = f(A);
2 G = g(F);
3 B = h(G);
This piece of code consists of three statements. The first statement takes data structure A as input to function f and it produces some output data F. Similarly function gproduces G and h produces B. Since F is used as input to function g and G is used as input to function h, there is a data dependence f, g and h, respectively.
This is a sequence pattern and can be illustrated with the figure to the left below.

A sequence pattern
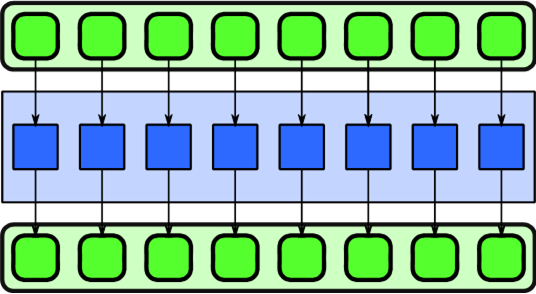
The Map Pattern
The green boxes with rounded squares represent data, a blue square represent a task (a piece of computation to be done on some data) and the arrows between data and/or tasks represent a dependence. Note here that the data structure F and G are not visible in the pattern as they are not needed to express the data dependency. The code could have been written like B = h(g(f(A))) instead.
The Map pattern
To the right above, the map pattern is shown. This pattern consists of applying (mapping) the same function (let’s call it foo(X)) to different parts of some input data. In essence it’s the sequence pattern repeated horizontally. In order for this pattern to be meaningful, it’s important that each vertical strand operates on different data.
This kind of pattern is also called embarrasingly parallel as each invokation of foo can happen in parallel with any other given that there is no dependence between them.
Code
Even this simple pattern becomes very abstract without some examples, so let’s look at some code:
void map_for(vector<int> &arr, std::function<int(int)> foo) {
for (long i = 0; i < arr.size(); ++i) {
arr[i] = foo(arr[i]);
}
}
This is a typical example of the map pattern implemented sequentially. The function map_for applies the same function foo to each element of the input array arr. Each invokation could happen in parallel with any or all others, as they are independent, but in this code it’s all sequential.
For those of us who are not fond of for-loops, C++ has an algorithm that does this for us:
void map_stl(vector<int> &arr, std::function<int(int)> foo) {
transform(arr.begin(), arr.end(), arr.begin(), foo);
}
The transform algorithm performs an operation on each item of a data-structure and writes the result back in another. In this example I re-use the input vector and I have wrapped it in the same interface so that it can be called in exactly the same way as the for-loop based map function.
Ok, but how do we make it parallel? We will investigate a few different options here: simple C++ threads, OpenMP, TBB and the (not so longer) new C++17 library parallel execution policy for algorithms.
C++ threads
Let’s first try to organise it manually using the C++ thread interface. Here is the code:
1 void map_threads(vector<int> &arr, std::function<int(int)> const &foo) {
2 const auto num_procs = std:🧵:hardware_concurrency();
3
4 vector<thread> tpool(num_procs); // create a thread pool
5
6 for (int p = 0; p < num_procs; p++) {
7 tpool[p] = thread([&arr, &foo, p, num_procs]() {
8 size_t my_start = arr.size() / num_procs * p;
9 size_t my_end = arr.size() / num_procs * (p + 1);
10 if (p + 1 == num_procs) {
11 my_end = arr.size(); // make sure the last thread takes care of the rest of the array
12 }
13 for (long i = my_start; i < my_end; ++i) {
14 arr[i] = foo(arr[i]);
15 }
16 });
17 }
18
19 // wait for threads to finish
20 for (auto &t : tpool) {
21 t.join();
22 }
23
24 }
It’s using the same interface as the sequential versions above. Let’s see what is happening here. On line 4 I declare a vector of threads with the same number of elements as there are cores in the machine as determined on line 2. Then each thread gets a slice of the array to work on as determined on lines 8-10. The actual work is done on lines 13-14 and finally on lines 20-21 we wait for all threads to finish.
Not very cute but it works. At the heart of it, every attempt to raise the abstraction level boils down to something along these lines during execution. It’s fine for a static for-loop like this where each iteration takes approximately the same amount of time as any other. As soon as it becomes a little more complicated, though, it becomes very difficult to deal with raw threads like this.
OpenMP
Our next variant is using OpenMP which is a well known parallel programming API for C, Fortran and C++.
void map_openmp(vector<int> &arr, std::function<int(int)> const &foo) {
#pragma omp parallel for shared(arr, foo)
for (long i = 0; i < arr.size(); ++i) {
arr[i] = foo(arr[i]);
} // implicit barrier
}
As you see, it’s exactly the same as the sequential version except the line: #pragma omp parallel for shared(arr, foo). OpenMP is a directive based programming model (enhanced with a number of library functions). The paralleldirective spawns a team of threads and the code block after the directive will be executed by all threads. The fordirective is a worksharing construct which will divide the iterations of a for loop among the threads in the team. Most implementations (if not all) will divide them statically exactly the same way that’s done in the thread-version above. Finally, the shared(arr, foo) directive tells the compiler that the vector and function references will be shared among the threads in the team. This is the default behaviour but it’s always good to be explicit.
At the end of a worksharing construct, there is an implicit barrier which means that the threads will wait here for all other threads to have finished their execution of the for-loop.
Threading building blocks – TBB
The Threading building blocks from Intel is a popular parallel programming library for C++. It is really powerful and provides in general tremendous performance and, as I will explore in a subsequent blog post, it allows for compositional parallelism which I think is very important when you are building large systems.
Here is the TBB version:
void map_tbb(vector<int> &arr, std::function<int(int)> const &foo) {
parallel_for((size_t) 0, arr.size(), [&](int i) { arr[i] = foo(arr[i]); };
}
The map idiom is such an important concept that it has it’s own function in TBB: parallel_for. It takes, in this case, three arguments: the starting index 0, the end index + 1 arr.size(), and then a function which will be invoked on each index. Compared to previous models, this is a function inside a function and for this simple code, it really hurts the performance as you can see below.
As you can see, it becomes simpler and simpler, but wait, there’s more.
Parallel STL algorithm
Finally, since C++17, there is a way to execute most of the STL algorithms in parallel like this:
void map_parstl(vector<int> &arr, std::function<int(int)> const &foo) {
transform(std::execution::par, arr.begin(), arr.end(), arr.begin(), foo);
}
Just add std::execution::par as the execution policy and the tranform algorithm will execute in parallel.
Performance
Ok, so the above examples gives a small feeling for the programming effort in C++ for various ways to code the map pattern. Do they all perform the same?
The table below shows some performance numbers that I do not pretend are to the last digit accurate. As always, performance of computer programs run on real machines (and in this case on vmWare VM) have a great deal of variance. Anyway, the numbers are averages of 10 runs done consecutively doing a map operation (multiply by 2) on an array with 200 million integers.
| Variant | Time (s) | Speedup |
|---|---|---|
| Sequential | 0.319 s | |
| Threads | 0.049 s | 6.44 |
| OpenMP | 0.045 s | 7.07 |
| TBB | 0.067 s | 4.73 |
| ——————- | ———- | ———– |
| stl seq | 0.318 s | |
| stl par | 0.042 s | 7.57 |
All parallel codes perform quite similarly except for the TBB version which is remarkably worse. The reason for this is probably that I am here using the simplified version of the parallel_for which calls the map-function which each index element. There is another version which hands out ranges to the map-function which we will explore in the upcoming post on parallell map-reduce.
The code used in this post can be fond on github.
Next time I will look at how the map pattern can be coded in some other languages, in particular: Java, Python and Rust.